Do you know what is the file robots.txt and what is it? Would you like to know how you can block urls of your website so that Google bots not to crawl more?
In this article, we are going to talk about all this and much more so that you know how to use the robots.txt for seo the right way.
That is the robots.txt and what is it used for
The file Robots.txt, is a text file that we are going to be of vital importance if we take a look at seo in a professional way.
The logic of that there is this document, and that is so commonly used by professionals in the organic positioning, is the following:
When we climbed up an online website, the way that Google has to index, and to position our content in the search engines, it is through their own robots or spiders of Google.
In this way, these bots to enter in our web, and begin to crawl across the site, jumping from url to url using anchors text-and-bound procedure (here the importance of working out a good strategy of interlinking).
But that's not all: Obviously, these spiders do not have all the time in the world to crawl our site, and that is why we have a crawl Budget for each time you enter our website. Note: * When we talk about crawl Budget or budget tracking, we refer to the maximum time that will be the Google bots are crawling our website.
That said: as these spiders have limited time, will be of vital importance to guide for when you come to our site, go to to crawl urls of greater importance vs the less important (and because we do not say we do not want that index, otherwise, you will be wasting your time).
Thus, the robots.txt it is a guide or a map that will serve to Google to find out the urls that should be given priority in the crawl, and consequently, for those that do not should waste time tracking.
So, in this guide, we will specify the urls that we want to track, and block those that do not want you to follow.
IMPORTANT: it is Not mandatory to configure the robots.txt because Google is going to go anyway to track our website, and what you are going to keep making regularly, as it does with all sites. So yes, if we take a look at SEO in a professional way, or we have notions, it is recommended to configure and upload this file guide to our website, as we will be able to optimize the tracking of robots or spiders. This, obviously, is going to be another one of the important factors of seo.
Disclaimer:* If you do not set up the file robots.txt Google is going to rastearlo ALL (when we say “EVERYTHING”, we refer to all of the urls the internal which can be accessed through links).
This is a document that must climb to the root of our web site, and as we have already mentioned, that we use to prevent robots to crawl content that you do not want Google to index or display in their results.
Let's look at an example: let's imagine that we have e-commerce, which has a search bar so the user can find it products.

For each search that he does, it will generate a url that can be more or less like this: www.example.com/catalogsearch/result?q=hola
Obviously, this type of urls are not going to want to index. So who better to save the time of crawling robots to to focus focus on crawlear the urls more important.
Regulations of the file Robots.txt
- The file should be called robots.txt: by this we mean that, unlike the sitemap.xml (that can be called in different ways), the file of robots can only be called one-way for Google to identify it correctly: “Robots.txt” (and obviously, you must be in text format).
- There can be only one file robots.txt website: This is super important. And is that, if we have to update the file, the way to do this correctly is to overwrite the information in the same document. You should NEVER create another separate document.
- The file robots.txt should be included in the root of the host of the website to which it is applied: as we have pointed out in the introduction, this file must be included in the root of the web. If you are using content management systems like WordPress, Prestashop or other, usually you'll find extensions that you are going to allow to integrate this text file makes it easy and convenient.
- The system of rules distinguishes between uppercase and lowercase letters: This will be important when configuring the orders. Otherwise, it may be that the order is not run as we want.
How to check the Robots.txt
To verify that the file of robots we have configured it correctly, we will need to access the checker robots.txt, where we may verify that you are meeting the rules that we have specified.
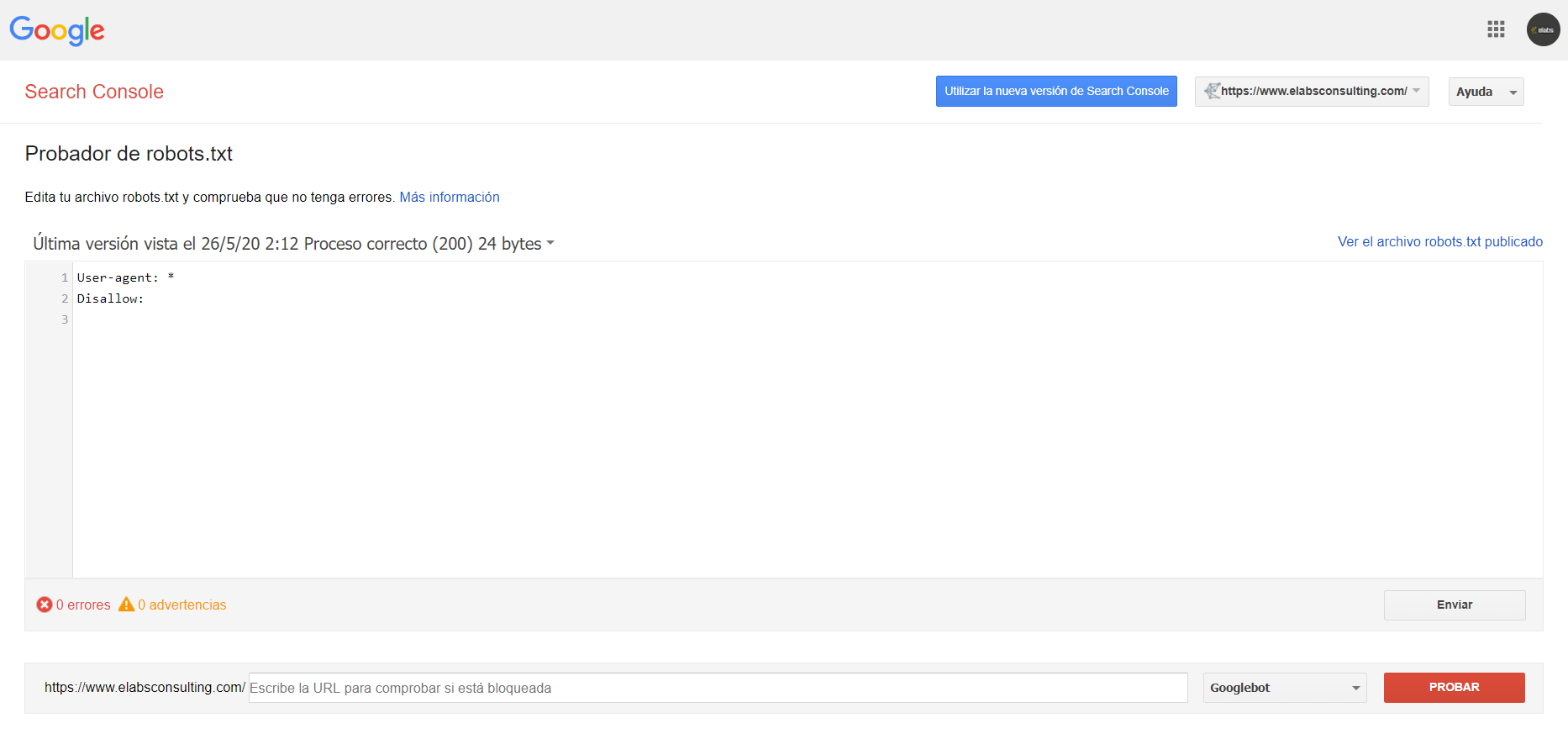
Once we have accessed the checker robots.txt, we will find a screen like this.
Here we are going to see the same thing that a user can see normal and stream by typing in the Google search bar to your domain + “/robots.txt”.
Example: www.elabsconsulting.com/robots.txt
In this image, we can see as we're saying to the robots that access to scan the entire content of the website, without any type of restriction.
Commands to the robots
User-agent: or agent user, are the robots or spiders of the search engines, you can see most of them in this database of web robots.
Google: Googlebot
Google Images: Googlebot-Image
Bing: Bingbot
Yahoo: Slurp
Baidu: Baiduspider
DuckDuckGo: DuckDuckBot
“Disallow:” tells the user agent or user agent that should not to access, track, or to index a URL, subdirectory, or specific directory.
Practical application:
“Allow:” arises as against to the previous one. with him indicas to the tracker URL, subdirectory or directory if you must enter, track, or index.


Guidelines advanced Robots.txt
Then, here are some of the guidelines or commands to more advanced that we are regularly in Elabs, so that you can include in your file Robots.txt.
User-agent: *
Disallow: /c?*
Disallow: /login-action.html
Disallow: /login.html
Disallow: /register.html
Disallow: /*|
Disallow: /*lvr=
Disallow: /*sel=
Disallow: /*prmax=
Disallow: /*prmin=
Disallow: /*lux=
If you would like more information about how to deploy the file robots.txt or how to use it, you can read more here.
How to create a file robots.txt
In view of the practical application of the robots.txt and its guidelines more popular, we see how to create one:
To make it easy, I recommend what you think with notepad, because we'll be able to easily save in text format (.txt).
Step 1: We open the blog notes.
Step 2: We wrote the first guideline mandatory:
User-agent: *
(With this, you are telling Google that we want access to track our website all the bots that exist: the spiders of Google, Bing, Ahrefs, Duck Duck Go...).
Otherwise, if we want to prohibit the entry of a robot (for example the “Bing”), must indicate:
User-agent: Bingbot
Step 3:
Then, we will start to give you more specific instructions that we want the robots to follow, for example, which do not take into account all the urls (useful for when we have a test environment or QA), or that does not take into account certain types of urls.
Example of which we don't want to track ANYTHING from our website:
User-agent: *
Disallow: /
Example of which we don't want to track some urls with parameters specific to our web site:
User-agent: *
Disallow: /*?order=
Disallow: /*?tag=
Disallow: /*?id_currency=
Disallow: /*?search_query=
Disallow: /*?back=
Disallow: /*?n=
Comment*: You can that throughout the analysis of a file robots.txt we find a piece of text preceded by “#”.
The use of the hashtag, pad or # in robots.txt, is simply to indicate a comment. But the text that will be followed just after this symbol, you are not going to have an influence on the orders of the rob

